
 MySQL
MySQL
# 安装
配置环境
在MySQL根目录下的 bin文件 在 变量 Path 增添 。如
D:\MySQL\mysql-8.0.22-winx64\bin
配置文件
在MySQL根目录下的新建 my.ini文件 和 data文件夹 , 配置参数
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
# 设置3306端口
port = 3306
# 设置MySQL根目录
basedir=D:\MySQL\mysql-8.0.22-winx64
# 设置MySQL数据库数据存放目录
datadir=D:\MySQL\mysql-8.0.22-winx64\data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为UTF8
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
# 设置时间戳
explicit_defaults_for_timestamp=true
安装MySQL
初始化数据库 在MySQL的根目录 bin文件夹 里 ,管理员身份打开cmd执行指令
mysqld --initialize-insecure --user=mysql
查看是否安装 然后安装执行,cmd执行指令
mysqld install
如果未提示成功,请用管理员身份打开重新执行cmd执行指令
启动MySQL服务。cmd执行指令
net start mysql
也可以在 控制面板 打开服务 进行启动 MySQL服务
进入myslq,无密码执行,cmd执行指令
mysql -uroot -p
PS:如果本地IP访问不到,需要重新启动服务,在cmd 进入
bin文件夹进行启动服务
# 卸载
- 管理员运行cmd关闭 MySQL服务,cmd执行指令
net stop mysql8
- 删除MySQL服务
sc delete mysql8
或者
mysql remove mysql8
- 删除mysqlDB目录文件(安装MySQL时my.ini指定的目录)
# 数据类型
# 整型数据
| 整型数据 | 字节数 | 无符号的取值范围 | 有符号的取值范围 |
|---|---|---|---|
| TINYINT | 1 | 0~225 | -125~127 |
| SMALLINT | 2 | 0-65535 | -32768~32768 |
| MEDIUMINT | 3 | 0~16777215 | ··· |
| INT | 4 | 0-4294967295 | ··· |
| BIGINT | 8 | 0~18446744073709551615 |
# 浮点型
| 浮点型 数据 | 字节数 | 说明 |
|---|---|---|
| FLOAT[(M,D)] | 4 | M指定显示长度,D指定小数位数,浮点 |
| DOUBLE[(M,D)] | 8 | M指定显示长度,D指定小数位数,浮点 |
| 定点数型数据 | - | - |
| DECIMAL(()M , 2) | M+2 | 定点数,存储 高精度数据 |
# 日期 时间类型
| 数据类型 | 字节数 | 取值范围 | 日期格式 | 零值 |
|---|---|---|---|---|
| YEAR | 1 | 1901~2155 | yyyy | 0000 |
| DATE | 4 | 1000-01-01-9999-12-3 | yyyy-MM-dd | 0000-00-00 |
| TIME | 3 | -838:59:59-838:59:59 | HH:mm:ss | 00:00:00 |
| DATETIME | 8 | 11 | yyyy-MM-dd HH:mm:ss | 0000-00-00 00:00:00 |
| TIMESTAMP(时间戳) | 4 | 1970-01-01 00:00:01~2038-01-19 03:14:07 | yyyy-MM-dd HH:mm:ss | 0000-00-00 00:00:00 |
# 字符串型
| 字符串类型(单位:字节) | 字节状态 | 优点 |
|---|---|---|
| CHAR((int)Max) | 固定 | 查询快 |
| VARCHAR((int)Max) | 动态 | 省空间 |
# 二进制数据类型
| 二进制数据类型(单位:长度) | 长度状态 |
|---|---|
| BINARY((int)Max) | 固定 |
| VARBINARY((int)Max) | 动态 |
BINARY类型的长度是固定的,如果长度不足最大长度,后面用“0”对齐,直到指定长度。
# 大文本数据类型
| 大文本数据类型 | 存储范围(单位:字节) |
|---|---|
| TINYTEXT | 0~255字节 |
| TEXT | 0~65535字节 |
| MEDIUMTEXT | 0~16777215字节 |
| LONGTEXT | 0~4294967295字节 |
# 大数据二进制类型
| 特殊二进制类型 | 存储范围(单位:字节) |
|---|---|
| TINYBLOB | 0~255字节 |
| BLOB | 0-65535字节 |
| MEDIUMBLOB | 0~16777215字节 |
| LONGBLOB | 0-4294967295字节 |
# 枚举型
ENUM枚举型,单选项
ENUM('值1','值2'···'值n')
# 多选项
SET('值1','值2'···'值n')
# DDL 库操作
DDL (Data Definition Language):数据定义语言,操作增删改查的操作
**操作关键字 : ** CREATE , DROP , ALTER , SHOW , USE
# 创建数据库
| SQL语句 | 说明 |
|---|---|
| ==CREATE DATABASE 库名;== | 创建库 |
| ==CREATE DATABASE IF NOT EXISTS 库名;== | 判断不存在,则创建 |
| ==CREATE DATABASE 库名 CHARACTER SET 编码方式;== | 指定编码创建 |
| ==CREATE DATABASE 库名 CHARACTER SET 编码方式 COLLATE 排序规则;== | 指定编码和排序规则创建 |
CREATE DATABASE :创建数据库 IF NOT EXISTS :检查是否已存在的状态 CHARACTER SET:设置编码方式 COLLATE :排序规则
# 查看数据库
查看当前数据库: ==SHOW DATABASES;==
查看创建的库: ==SHOW CREATE DATABASE 库名;==
查看当前所选的数据库: ==SELECT DATABASE();==
# 修改数据库
| SQL语句 | 说明 |
|---|---|
| ==ALTER DATABASE 库名;== | 修改库 |
| ==ALTER DATABASE 库名 CHARACTER SET 编码方式;== | 指定编码更改 |
| ==ALTER DATABASE 库名 CHARACTER SET 编码方式 COLLATE 排序规则;== | 指定编码和排序规则更改 |
ALTER DATABASE :修改数据库 IF NOT EXISTS :检查是否已存在的状态 CHARACTER SET :设置编码方式 COLLATE :排序规则
# 删除数据库
==DROP DATABASE 库名;==
# 选择数据库
==USE 库名;==
# DDL 表操作
DDL (Data Definition Language):数据定义语言,定义数据库对象:库、表、列等
**操作关键字 : ** CREATE , DROP , ALTER , SHOW , USE
# 创建表
CREATE TABLE 表名(
字段名1 数据类型 [完整性约束条件] [COMMENT '注释内容'],
字段名2 数据类型 [完整性约束条件] [COMMENT '注释内容'],
·······
字段名n 数据类型 [完整性约束条件] [COMMENT '注释内容'],
[完整性约束条件](字段1,字段2,·····,字段n)
)[编码集设置];
**编码集设置 : ** CHARACTER SET 字符集名 [校对规则] **校对规则 : ** COLLATE 校对名
快速创建拷贝表
CREATE TABLE 表名 AS SELECT * FROM 拷贝表
PS : AS 后面 是拷贝制定查询的数据
# 查看表
查看指定表字段结构 ==DESC 表名;==
查看当前数据库所有表 ==SHOW TABLES;==
查看表的详细结构 ==SHOW CREATE TABLE 表名;==
# 修改表
修改表名
==RENAME TABLE 表名 TO 新表名;== ==ALTER TABLE 表名 RENAME 新表名;==
增加字段
==ALTER TABLE 表名 ADD 字段名 数据类型;==
字段 修改 与 顺序
ALTER TABLE 表名 MODIFY 字段名 数据类型 [更改字段循序 | 完整性约束条件] [COMMENT '内容'];
更改字段循序 : FIRST | AFTER 字段名2
FIRST:指定字段为表的第一个 AFTER:指定字段插入字段2的后面
修改字段名
==ALTER TABLE 表名 CHANGE 字段名 新字段名 新字段类型;==
修改表字符集
==ALTER TABLE 表名 CHARACTER SET 字符集类型;==
删除字段
==ALTER TABLE 表名 DROP 字段名;==
# 删除表
==DROP TABLE 表名;==
# DML 数据操作
DML (Data Manipulation Language):数据操作语言,定义数据库记录(数据)增删改 的操作
**操作关键字 : ** INSERT , UPDATA , DELECT
# 插入数据
一条数据添加 ==INSERT INTO 表名 [(字段名1 [,字段名2. . .])] VALUES(值1 [,值2. . .]);== 多条数据添加 ==INSERT INTO 表名 [(字段名)] VALUES (字段值1),(字段值2)...;==
注意:
- 插入字段与它的数据类型位置是一一对应的
- 数据类型对应的值,字段值是非数值,则两侧必须添加单引号
- null设置为空
- 数据的大小应在字段的数据类型规定范围内
- 如果要插入所有字段数据时可以省写字段,但必须按表中字段顺序写值
- 尽可能避免字段数据值写入的是
null
# 更改数据
更改单表数据 ==UPDATE 表名 SET 字段名1 = 字段值1 [,字段名2 = 值2..] [WHERE 条件表达式];== 更改多表数据 ==UPDATE 表名1 , 表名2 SET {修改字段值,可跨表修改} [WHERE 条件表达式];==
注意:
- 逻辑运算符有: and(并且)、or(或者)、not(取非)
- 如果更改字段无条件表达式,则指定全部该字段的值一致
# 删除数据
==DELETE FROM 表名 [WHERE 条件表达式];== ==TRUNCATE TABLE 表名;== 多表删除 ==DELETE {表名1,表名2...} FROM {表名1,表名2...} [WHERE 条件表达式];==
注意:
- 如果无条件表达式,则删除全部数据
- DELETE删除可找回
- TRUNCATE删除不可找回,类似格式化数据,执行快
- 不能删除某列的值(可修改数据值置NULL)
- 多表删除 建议WHERE过滤他们字段的关系
- 多表中的每张表需要逗号分隔
# DCL 安全访问
DCL (Data Control Language)︰数据控制语言,用来定义访问权限和安全级别
操作关键字: GRANT , REVOKE
# 创建用户
==CREATE USER '用户名'@'指定ip' IDENTIFIED BY '密码';== ==CREATE USER '用户名'@'%' IDENTIFIED BY '密码';==
指定ip / 任意ip 可登录
==CREATE USER 'bozhu'@'%' IDENTIFIED BY '123123';==
# 授权用户
==GRANT 权限1[,权限2...权限n] ON 库名.* TO '用户名'@'指定ip';==
==GRANT ALL ON *.* TO '用户名'@'指定ip';==
指定权限 / 所有权限 用户授权 (指定权限自行查询)
==GRANT ALL PRIVILEGES ON *.* TO 'bozhu'@'%' IDENTIFIED BY 'bozhu' WITH GRANT OPTION;==
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' WITH GRANT OPTION;
# 查询权限
==SHOW GRANTS FOR 用户名@指定IP;== ==SHOW GRANTS FOR 用户名@‘%’;==
查询指定 / 查询所有 IP的权限情况
# 撤销权限
==REVOKE 权限1[,权限2...权限n] ON 库名.* FROM 用户名@指定IP;==
# 删除用户
==DROP USER 用户名@指定IP==
# 权限刷新
==flush privileges;==
修改后需要刷新生效权限
# DQL 数据查询
DQL(Data Query Language):数据查询语言,用来查询记录(数据)查询 数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端 查询返回的结果集是一张虚拟表
操作关键字: SELECT
SELECT的语法结构:
SELECT (* | {字段名1 [别名][,字段名2[别名]····,字段名n[别名]]} ) FROM 表名 [可选参数];
SELECT * FROM 表名;
参数:
[WHERE 条件表达式];
[GROUP BY 字段名 [HAVING 条件表达式2]] ;
[ORDER BY 字段名 [ASC | DESC]];
[LIMIT [OFFSET] (int)记录数];
别名:代替字段名
**DISTINCT:**过滤表字段中重复的值(数据),如果指定是多个字段,而且指定的字段值相同,则过滤重复的值!!!
**WHERE:**指定查询条件
**GROUP BY:**将查询结果按指定字段进行分组
- **HAVING:**对分组后的结果进行过滤
**ORDER BY:**将查询结果按指定字段进行排序,排列方式有参数ASC(升序)、DESC(降序)控制,默认为ASC(升序)
**LIMIT:**限制查询结果的数量,后面有可有两个参数
- **OFFSET:**表示偏移量,如果偏移量为0则从第一条开始,。不指定参数1,其默认值为0。
- **记录数:**表示返回查询记录的条数
# 普通查询
# 条件查询 (WHERE)
··· WHERE (条件表达式);
# 查询 age大于等于25
SELECT * FROM stu WHERE age>=25;
# 查询 age大于等于25 指定显示 sname
SELECT sname FROM stu WHERE age>=25;
# 查询 指定gender值非male
SELECT * FROM stu WHERE gender!='male';
SELECT * FROM stu WHERE gender<>'male';
SELECT * FROM stu WHERE NOT gender='male';
# 指定查询 (IN)
查指定字段
··· WHERE 字段名 [NOT] IN (值1,值2,···);
# 查询 指定sid
SELECT * FROM stu WHERE sid IN ('S_1011' , 'S_1004');
# 查询 指定sid
SELECT * FROM stu WHERE sid NOT IN ('S_1011' , 'S_1004');
# 范围查询 (BETWEEN AND)
查指定字段的范围值
··· WHERE 字段名 [NOT] BETWEEN (int)值1 AND (int)值2;
# 查询 指定age 12 - 28的范围
SELECT * FROM stu WHERE age BETWEEN 12 AND 28;
# 查询 指定age 非12 - 28的范围
SELECT * FROM stu WHERE age NOT BETWEEN 12 AND 28;
查询字段名的值1和值2的范围,前提2值必须大于1值
# 空值查询 (NULL)
查字段NULL值
··· WHERE 字段名 IS [NOT] NULL;
# 查询 age为空的
SELECT * FROM stu WHERE age IS NULL;
# 查询 gender不为空的
SELECT * FROM stu WHERE gender IS NOT NULL;
# 过滤查询 (DISTINCT )
过滤重复字段
SELECT DISTINCT * | {字段1,字段2...字段n} FROM 表名 [···];
# 查询表中不重复的字段
SELECT DISTINCT * FROM stu;
# 模糊查询 (LIKE)
寻找匹配的字符串
··· WHERE 字段名 [NOT] LIKE '匹配字符串%_';
# 查询 sname 前缀有字符 l
SELECT * FROM stu WHERE sname LIKE 'l%';
# 查询 sname 第5个字符为 S
SELECT * FROM stu WHERE sname LIKE '_____S%';
注意:
%任意0 - n个字符_一个字符,通配符(未知数)\进行转义\%为%
# 多条件查询 (AND)
(交集)连接两个或者多个查询条件
··· WHERE 条件表达式1 [AND 条件表达式2 [··· AND 条件表达式n]];
#查询 age>16 && age<28
SELECT * FROM stu WHERE age>16 AND age<28;
#查询 age>16 && age<28 且不能有 25
SELECT * FROM stu WHERE age>16 AND age<28 AND age != 25;
# 多条件查询 (OR)
(并集)记录满足任意一个条件即被查出
··· WHERE 条件表达式1 [OR 条件表达式2 [··· OR 条件表达式n]];
# 查询 age<16 || age>28
SELECT * FROM stu WHERE age<16 OR age>28;
# 查询 age<16 || age>28 且不能有 5
SELECT * FROM stu WHERE age != 5 AND age<16 OR age>28;
OR和AND一起用的情况: AND的优先级高于OR,因此当两者在一起使用时,应该先运算AND两边的条件表达式,再运算OR两边的条件表达式
# 高级查询
# 聚合函数
# 记数函数 (COUNT)
统计不为null的记录条数
SELECT COUNT((*) | (字段名))
FROM 表名 [···];
# 查询 emp2表 总记录数
SELECT COUNT(*) FROM emp2 ;
# 查询 emp2表 comm记录数
SELECT COUNT(comm) FROM emp2 ;
# 求和函数 (SUM)
求出表中某个字段所有值的总和
SELECT SUM(字段名1)[,SUM(字段名2)...,SUM(字段名n)]
FROM 表名 [···];
# 查询 emp2表 sal字段总和
SELECT SUM(sal) FROM emp2;
# 查询 emp2表 sal+comm字段 总和(IFNULL(comm , 0) 如果字段值为NULL 则至为0)
SELECT SUM(sal+ IFNULL(comm , 0) ) FROM emp2;
# 平均值函数 (AVG)
求出某个字段所有值的平均值
SELECT AVG(字段名1)[,AVG(字段名2)...,AVG(字段名n)]
FROM 表名 [···];
# 查询 emp2表 sal字段平均值
SELECT AVG(sal) FROM emp2;
# 最大值函数 (MAX)
用于求出某个字段的最大值,语法格式:
SELECT MAX(字段名1)[,MAX(字段名2)...,MAX(字段名n)]
FROM 表名 [···];
# 查询 emp2表 mgr字段最大值
SELECT MAX(mgr) FROM emp2;
# 最小值函数 (MIN)
用于求出某个字段的最小值,语法格式:
SELECT MIN(字段名1)[,MIN(字段名2)...,MIN(字段名n)]
FROM 表名 [···];
# 查询 emp2表 mgr字段最小值
SELECT MIN(mgr) FROM emp2;
# 顺序查询 (ORDER BY)
对查询结果进行排序,语法格式:
SELECT * | {字段1,字段2...字段n} FROM 表名
ORDER BY 字段名1 [ASC | DESC] [,字段名2 [ASC| DESC]...,字段名n [ASC | DESC]];
# 查询 排序 emp2 表的 mgr(降序)
SELECT * FROM emp2 ORDER BY mgr DESC;
# 查询 排序 emp2表 的 先排序mar ,相同值的情况排序sal (默认升序)
SELECT * FROM emp2 ORDER BY mgr , sal;
ORDER BY:指定字段进行排序 SELECT:指定查询的字段 ASC升序(默认)、DESC降序
注意:指定字段升序排列时,某条字段值为NULL,则这条记录会在第一条显示,因NULL值被认为是最小值
# 分组查询 (GROUP BY)
对字段值进行分组查询
SELECT 字段名1 | [···] FROM 表名
GROUP BY 字段名1,字段2,···[HAVING 条件表达式 | ···];
# 查询 emp2表 以daptno字段分组 进行sal求和
SELECT deptno , SUM(sal) FROM emp2 GROUP BY deptno;
# 查询 emp2表 以daptno字段分组 每个dapthon分组的记录数 并排序
SELECT deptno , COUNT(*) FROM emp2 GROUP BY deptno ORDER BY deptno;
# 查询 emp2表 以daptno字段分组 deptno值为30 过滤
SELECT deptno , SUM(sal) FROM emp2 GROUP BY deptno HAVING deptno != 30;
# 查询 emp2表 以daptno字段分组 mgr值小于7800 过滤
SELECT deptno , COUNT(*) FROM emp2 WHERE mgr>7800 GROUP BY deptno;
注意:
- GROUP BY后面的字段 是指定字段进行分组
- 聚合函数一起使用
- 查询过滤使用
HAVING并非WHERE - HAVING不能单独出现,只能存在GROUP BY后面
- 非指定字段分组不能显示字段 如:(指定字段分组是deptno字段,但不能显示empno字段) SELECT empno , SUM(sal) FROM emp2 GROUP BY deptno;
- 指定分组的字段可进行排序
WHERE和HAVING区别
WHERE语句:分组前进行过滤,不能使用聚合函数 HAVING语句:分组后进行过滤,可使用聚合函数
# 限制查询 (LIMIT)
限制查询结果的数量
SELECT 字段名1[,字段名2,...字段n] FROM 表名
LIMIT [(int)偏移量,](int)显示数;
# 查询 emp2表 sal最小5个
SELECT * FROM emp2 ORDER BY sal LIMIT 0 , 5;
# 查询 emp2表 sal最大5个
SELECT * FROM emp2 ORDER BY sal DESC LIMIT 0 , 5;
批量分页查询的情况
如果有大量数据比如:10页,每页有10条 ,共有100条! 第一页0,第二页10,第三页20····第九页90
pagelndex 页码数、pagesize 每页显示的条数
==LIMIT (pageindex-1)*pagesize , pagesize;==
# 别名
在查询数据时,可以为表和字段取别名,这个别名可以代替其指定的表和字段。
# 表别名
可以为表取一个别名,用这个别名来代替表的名称。别名格式:
SELECT (* | 字段) FROM 表名 别名 [...];
AS:用于指定表名的别名,它可以省略不写。
# 字段别名
为字段取一个别名,用这个别名来代替表的名称。别名格式:
SELECT (* | 字段名1 [别名][,字段名2[别名]····,字段名n[别名]]) FROM 表名 [...];
# 或者:
SELECT (* | 字段名1 [AS 别名][,字段名2[AS 别名]····,字段名n[AS 别名]]) FROM 表名 [...];
# 多表关系
多对一 在多对一的表关系中,应将外键建在多的一方
多对多 为了实现数据表多对多的关系,需要定义第三方中间表来保存两个关系表的外键
一对一 一对一的对应关系中,需要分清主从关系,通常在从表中建立外键
表创建及测试调用例子 复制导入 sql脚本导入
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for category
-- ----------------------------
DROP TABLE IF EXISTS `category`;
CREATE TABLE `category` (
`cid` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`cname` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`cid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of category
-- ----------------------------
INSERT INTO `category` VALUES ('c001', '电器');
INSERT INTO `category` VALUES ('c002', '服饰');
INSERT INTO `category` VALUES ('c003', '化妆品');
INSERT INTO `category` VALUES ('c004', '书籍');
-- ----------------------------
-- Table structure for class
-- ----------------------------
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`classid` int(0) NOT NULL AUTO_INCREMENT,
`classname` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`classid`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of class
-- ----------------------------
INSERT INTO `class` VALUES (1, '红龙班');
INSERT INTO `class` VALUES (2, '卫冕班');
INSERT INTO `class` VALUES (3, '神州班');
INSERT INTO `class` VALUES (4, '航天班');
-- ----------------------------
-- Table structure for orderitem
-- ----------------------------
DROP TABLE IF EXISTS `orderitem`;
CREATE TABLE `orderitem` (
`oid` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`pid` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of orderitem
-- ----------------------------
-- ----------------------------
-- Table structure for orders
-- ----------------------------
DROP TABLE IF EXISTS `orders`;
CREATE TABLE `orders` (
`oid` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`totalprice` double NULL DEFAULT NULL,
`uid` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`oid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of orders
-- ----------------------------
-- ----------------------------
-- Table structure for products
-- ----------------------------
DROP TABLE IF EXISTS `products`;
CREATE TABLE `products` (
`pid` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`name` varchar(40) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`price` double NULL DEFAULT NULL,
`category_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`pid`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of products
-- ----------------------------
INSERT INTO `products` VALUES ('p001', '联想', 5000, 'c001');
INSERT INTO `products` VALUES ('p002', '海尔', 3000, 'c001');
INSERT INTO `products` VALUES ('p003', '雷神', 5000, 'c001');
INSERT INTO `products` VALUES ('p004', 'JACKJONES', 800, 'c002');
INSERT INTO `products` VALUES ('p005', '真维斯', 200, 'c002');
INSERT INTO `products` VALUES ('p006', '花花公子', 440, 'c002');
INSERT INTO `products` VALUES ('p007', '劲霸', 2000, 'c002');
INSERT INTO `products` VALUES ('p008', '香奈儿', 800, 'c003');
INSERT INTO `products` VALUES ('p009', '相宜本草', 200, 'c003');
INSERT INTO `products` VALUES ('p010', '梅明子', 200, NULL);
-- ----------------------------
-- Table structure for scores
-- ----------------------------
DROP TABLE IF EXISTS `scores`;
CREATE TABLE `scores` (
`sid` int(0) NOT NULL AUTO_INCREMENT,
`score` int(0) NULL DEFAULT NULL,
`subjectid` int(0) NULL DEFAULT NULL,
`studentid` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`sid`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 13 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of scores
-- ----------------------------
INSERT INTO `scores` VALUES (1, 43, 1, 1);
INSERT INTO `scores` VALUES (2, 100, 2, 1);
INSERT INTO `scores` VALUES (3, 54, 3, 1);
INSERT INTO `scores` VALUES (4, 34, 1, 2);
INSERT INTO `scores` VALUES (5, 52, 2, 2);
INSERT INTO `scores` VALUES (6, 32, 3, 2);
INSERT INTO `scores` VALUES (7, 41, 1, 3);
INSERT INTO `scores` VALUES (8, 86, 3, 3);
INSERT INTO `scores` VALUES (9, 98, 2, 3);
INSERT INTO `scores` VALUES (10, 78, 3, 4);
INSERT INTO `scores` VALUES (11, 76, 2, 4);
INSERT INTO `scores` VALUES (12, 54, 1, 4);
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`studentid` int(0) NOT NULL AUTO_INCREMENT,
`studentname` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`sex` char(1) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`classid` int(0) NULL DEFAULT NULL,
`test` int(0) NULL DEFAULT NULL,
PRIMARY KEY (`studentid`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 10 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of student
-- ----------------------------
INSERT INTO `student` VALUES (1, '黑猫', '111111', '女', 1, 10);
INSERT INTO `student` VALUES (2, '大鲸', '2222', '男', 3, 20);
INSERT INTO `student` VALUES (3, '白兔', '3333', '女', 3, 30);
INSERT INTO `student` VALUES (4, '柏竹', '4444', '男', NULL, 40);
INSERT INTO `student` VALUES (5, '棕熊', '5555', '男', 5, 50);
INSERT INTO `student` VALUES (6, '智乃', '6666', '女', 3, 60);
INSERT INTO `student` VALUES (7, '蕾姆', '7777', '女', 2, 70);
INSERT INTO `student` VALUES (8, '艾米', '8888', '女', 1, 80);
INSERT INTO `student` VALUES (9, '纱雾', '9999', '女', 2, 90);
-- ----------------------------
-- Table structure for subject
-- ----------------------------
DROP TABLE IF EXISTS `subject`;
CREATE TABLE `subject` (
`subjectid` int(0) NOT NULL AUTO_INCREMENT,
`subjectname` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`subjectid`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of subject
-- ----------------------------
INSERT INTO `subject` VALUES (1, 'Java');
INSERT INTO `subject` VALUES (2, 'MySQL');
INSERT INTO `subject` VALUES (3, 'HTML');
-- ----------------------------
-- Table structure for users
-- ----------------------------
DROP TABLE IF EXISTS `users`;
CREATE TABLE `users` (
`userid` int(0) NULL DEFAULT NULL,
`username` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`upass` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of users
-- ----------------------------
SET FOREIGN_KEY_CHECKS = 1;
# 连接查询(CROSS JOIN)
交叉连接又称 笛卡尔积 ,返回结果的是 被连接的两个表中所有字段行乘积
SELECT {* | 查询字段} FROM 表1 CROSS JOIN 表2 [WHERE 条件表达式];
# 或者(简写)
SELECT {* | 查询字段} FROM 表1,表2 [WHERE 条件表达式];
# 将学生与班级交叉查询
SELECT * FROM student CROSS JOIN class;
# 自然连接(NATURAL JOIN)
特殊的等值连接,前提两表字段属性必须相同,且字段名也要相同,无须添加连接条件,得出的结果是消除重复的字段
SELECT {* | 查询字段} FROM 表1 NATURAL JOIN 表2;
# 查询学生所在的班级
SELECT * FROM student NATURAL JOIN class;
# 合并结果集 (UNION)
连接查询的过程中,通过添加过滤条件来限制查询结果,使查询结果更加精确(ALL去除重复的记录)
应用场景:
- 查询列数类型一致可合并!!!
- 查询两表相同列数类型进行合并结果
SELECT {* | 查询字段} FROM 表1 UNION [ALL]
SELECT {* | 查询字段} FROM 表2;
# 合并两表数据
SELECT studentid,studentname FROM student UNION
SELECT subjectid,subjectname FROM subject;
注意: 合并前提必须将两表的列数和类型一致
# 内连接 (INNER JOIN)
内连接使用 比较运算符,对两表中指定字段值进行比较,列出与连接条件匹配的数据行 ,字段值符合匹配的进行连接,组合成新的记录(无视不匹配的字段)
两表满足条件才会显示 , 否者无视
#
SELECT {* | 查询字段} FROM 表1 INNER JOIN 表2 ON {表1.关系字段 = 表2.关系字段 | WHERE 条件表达式} ;
# 或者 SQL92写法
SELECT {* | 查询字段} FROM 表1,表2 WHERE 表1.关系字段 = 表2.关系字段;
# 或者 SQL99写法
SELECT {* | 查询字段} FROM 表1 JOIN 表2 ON 表1.关系字段 = 表2.关系字段 WHERE 约束;
# 查询 与班关联的学生(已经分配班级的学生)
SELECT * FROM student JOIN class ON student.classid = class.classid;
# 查询花子所有成绩
SELECT subjectname,score
FROM
scores , subject , student
WHERE
scores.subjectid = subject.subjectid
AND scores.studentid = student.studentid
AND student.studentname = '花儿';
# 查询 所有科目的平均值
SELECT subjectname , AVG( score )
FROM
scores JOIN subject
ON scores.subjectid = subject.subjectid
GROUP BY
subjectname;
# 外连接 (OUTER JOIN)
外连接 弥补了内连接查询不匹配的条件,查出不满足条件的可能 外连接包括: 左连接 / 右连接
左连接 指定左表的所有记录,所有满足连接条件的记录。如果左表的某条记录在右表中不存在,则在右表中显示为空值
主表 为左边,从表 为右边
右连接 右连接与左连接正好相反
主表 为右边,从表 为左边
# 可将 {LEFT|RIGHT} OUTER JOIN 进行缩写为 {LEFT|RIGHT} JOIN
SELECT {*|查询字段} FROM 主表 {LEFT|RIGHT} JOIN 从表 ON 主表.字段 = 从表.字段;
# 左外连接
SELECT {*|查询字段} FROM 主表 LEFT JOIN 从表 ON 主表.字段 = 从表.字段;
# 右外连接
SELECT {*|查询字段} FROM 主表 RIGHT JOIN 从表 ON 主表.字段 = 从表.字段;
# 左外查询
SELECT * FROM
student LEFT JOIN class
ON student.classid = class.classid;
# 右外查询
SELECT * FROM
student RIGHT JOIN class
ON student.classid = class.classid;
注意: 主表会显示所有字段,空值或不匹配条件的字段均可查询!!!
# 子查询
子查询是指一个查询语句 嵌套在另一个 查询语句内部的查询 在执行查询语句时,首先会执行子查询中的语句,然后将返回的结果作为外层查询的过滤条件,子查询必须返回是一个字段数据
# where中子查询
常用于聚合函数的子查询 比较 约束(子查询只能单条结果)
SELECT * FROM 表 WHERE ...(子查询)
# 查询和 智乃 同班的学生
SELECT studentname FROM student WHERE classid = (
SELECT classid FROM student WHERE studentname = "智乃"
);
# from中子查询
将子查询的临时表当做一个表进行应用 (子查询能多条结果)
SELECT * FROM (子查询) 别名 WHERE ...
# 查出每个同学所有科目的平均分数
SELECT studentname,c.avg FROM (
SELECT sid,avg(score) avg FROM scores GROUP BY sid
)c JOIN student s ON c.sid = s.studentid
PS : 使用临时表需要手动指定表名
# select中子查询
将结果进行展示,在 两表有字段关联约束进行查询使用(子查询只能单条结果)
SELECT (子查询),... FROM 表
# IN
内层查询语句仅仅返回一个数据字段,数据字段中的值将供外层查询语句进行比较操作
SELECT {* | 查询字段} FROM 表名1 WHERE 字段 [NOT] IN(SELECT 字段 FROM 表名2 WHERE 条件表达式);
# 查询 三班有多少女生
SELECT studentname FROM student WHERE classid IN(
SELECT classid FROM class WHERE classid = 3
)AND sex = '女';
# 查询 与‘智乃’同一个班的学生
SELECT studentname FROM student WHERE classid IN(
SELECT classid FROM student WHERE studentname = '智乃'
);
注意: IN 后面子查询返回结果要和IN前的字段匹配
# EXISTS
参数可以是任意一个子查询, 这个子查询的作用相当于测试,返回 布尔值 , 如果 TRUE 外层查询才会执行
SELECT {* | 查询字段} FROM 表名1 WHERE [NOT] EXISTS (SELECT 字段 FROM 表名2 WHERE 条件表达式);
# 测试 两表关系(匹配显示,不匹配不显示)
SELECT
studentid,
studentname
FROM student WHERE
EXISTS ( SELECT * FROM class WHERE class.classid = student.classid );
# ANY
满足任意一个条件,子查询返回的字段列表进行比较,将不匹配的过滤
SELECT * FROM 表名 WHERE [NOT] 字段 {比较运算符} ANY(SELECT 字段 FROM 表名);
# 查询 已经分配班级的学生
SELECT classid,studentname FROM student
WHERE
classid = ANY(SELECT classid FROM class);
#或 (结果一样)
SELECT classid,studentname FROM student
WHERE
classid IN( SELECT classid FROM class);
# ALL
子查询返回的字段列表结果需同时满足所有内层查询条件,否则查询为空
SELECT * FROM 表名 WHERE [NOT] 字段 {比较运算符} ALL(SELECT 字段 FROM 表名);
# 查询 test 高于蕾姆的同学
SELECT studentname,test FROM student
WHERE
test > ALL(SELECT test FROM student WHERE studentname = '蕾姆');
# 查询 匹配错班级的同学(数据错乱)
SELECT classid,studentname FROM student
WHERE
classid > ALL(SELECT classid FROM class);
#或 (结果一样)
SELECT classid,studentname FROM student
WHERE
classid NOT IN( SELECT classid FROM class);
# 比较运算符
ANY 和 ALL 都用到比较运算符,但还可以使用其他运算符
SELECT * FROM 表名 WHERE [NOT] 字段 {比较运算符} (SELECT 字段 FROM 表名)
# 查新执行顺序
书写顺序:
SELECT DISTINCT ... FROM ... JOIN ... ON ... WHERE ...
GROUP BY ... HAVING ... ORDER BY ... DESC LIMIT ...
执行顺序:
FROMNOJOINWHEREGROUP BYAVG,SUM,...(聚合函数)HAVINGSELECTDISTINCTORDER BYLIMIT
# SQL优化
- 避免全表扫描,应先考虑 where 及 order by 涉及的列上建立索引
- 避免 where语句 中的字段进行
null值判断 - 避免 where语句 中使用
!=或</>操作符 - 避免 where语句 使用
OR连接条件 - 谨慎使用
IN/NOT IN进行查询,连续数字可使用BETWEEN范围查询
# 完整性
保证了数据的有效性和准确性,以防止数据表中插入错误的数据
| 约束条件 | 说明 |
|---|---|
PRIMARY KEY | 主键约束,用于唯一标识对应的记录 |
FOREIGN KEY | 外键约束 |
NOT NULL | 非空约束 |
UNIQUE [KEY] | 唯一性约束 |
DEFAULT | 默认值约束,用于设置字段的默认值 |
AUTO_INCREMENT | 自动增长 |
CHECK | 约束取值范围 |
UNSIGNED | 无符号约束 |
注意: 多个约束需要空格分隔
# 实体完整性
# 单字段主键
每表只有一个主键,唯一性,不能NULL,可创建联合主键 ==字段名 数据类型 PRIMARY KEY[(字段名1,字段名2,···字段名n)];== ==ALTER TABLE student ADD PRIMARY KEY[(字段名1,字段名2,···字段名n)]==
# 唯一约束
数据不能重复,只能有一次为空 ==字段名 数据类型 UNIQUE;==
# 字段自动增加
在数据表中,若想为表中插入的新记录自动生成唯一的 ID,可以使用自增约束来实现 ==字段名 数据类型 AUTO_INCREMENT;==
# 域完整性
# 数据类型
# 非空约束
字段的值不能为NULL(空) ==字段名 数据类型 NOT NULL;==
# 默认约束
新添数据时,如果未赋值,则自动插入默认值 ==字段名 数据类型 DEFAULT(默认值);==
# 无符号约束
==字段名 数据类型 UNSIGNED;==
# 约束范围
==字段名 数据类型 CHECK (字段值>0 and 字段值<=100);==
# 引用完整性
# 外键约束
外键是指引用另一个表中的一个字段或多个字段。建立、加强两表数据之间的链接
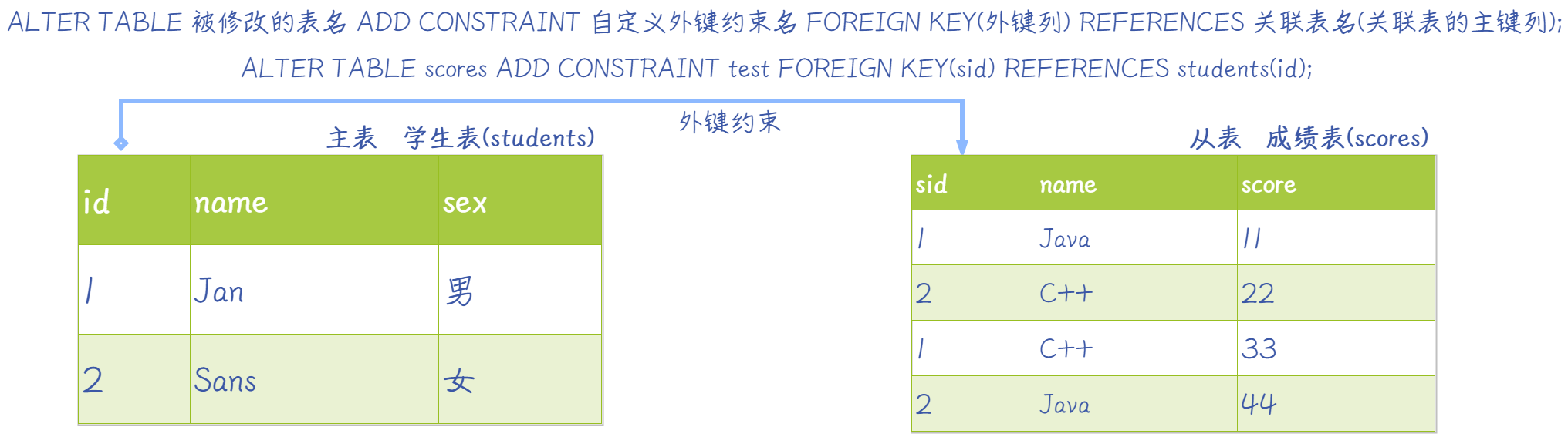
创建表时 定义外键:
# 从表
CREATE TABLE 表名(
字段名1 数据类型 [完整性约束条件],
字段名2 数据类型 [完整性约束条件],
·······
FOREIGN KEY (外键字段) REFERENCES 主表( 主表的 主键 / 唯一 字段 )
);
创建表后 定义外键: ==ALTER TABLE 从表 ADD CONSTRAINT [自定义外键名] FOREIGN KEY(从表 外键字段) REFERENCES 主表( 主表的 主键 / 唯一 字段 );==
外键查询 (查询表详细 可查询表的外键)
==SHOW CREATE TABLE 表名;==
外键删除
根据逻辑的需求,需要解除两个表之间的关联关系时,就需要删除外键约束 ==ALTER TABLE 表名 DROP FOREIGN KEY 外键名;==
注意:
- 主表是被外键引用的字段,且该字段有 主键约束/唯一性约束
- 被引用的是 主表,引用 的是 从表,两表是主从关系
- 引入外键后,从表 外键字段 只能插入主表被引用的字段值
- 如果想删除 主表 一条记录,则必须删除完 与主表相同外键值(对象是删除的记录)的从表外键字段记录(删除外键字段值与主表相同的值) ,主表才能进行删除记录,确保数据的完整性
- 建立外键的表必须是InnoDB型不能是临时表。因为MySQL中只有InnoDB型的表才支持外键
- 定义外键名时,不能加引号。如: 'FK_ ID' 或" FK_ID "都是错误的 ,
- 自定义外键名 用于删除外键约束时使用,也可不设置,一般建议“_fk”为结尾
# 索引
索引的目的在于提高查询效率,与我们查字典所用的目录是一个道理
优点:
- 提高查询效率
- 降低CPU使用率
缺点:
- 索引本身很大,存储在 内存/硬盘 中
- 索引会降低 增删改 的效率
索引分类:
主键和唯一的区别:主键不能为null,而唯一可以
# 索引创建
建表时创建索引:
CREATE TABLE 表名(
字段名1 数据类型 [完整性约束条件],
字段名2 数据类型 [完整性约束条件],
·····
字段名n 数据类型
[UNIQUE | FULLTEXT | SPATIAL] INDEX | KEY
[索引名] (字段名1 [长度]) [ASC | DESC])
)[存储引擎];
UNIQUE: 可选参数,表示唯一性约束 FULLTEXT:可选参数,表示全文约束 SPATIAL: 可选参数,表示空间约束 INDEX 和 KEY:用来表示字段的索引,二者选一即可 索引名:可选参数,表示创建的索引的名称 字段名1:指定索引对应字段的名称 长度:可选参数,用于表示索引的长度 ASC 和 DESC:可选参数,其中,ASC表示升序排列,DESC表示降序排列
# 单列索引 (NORMAL)
在表中单个字段上创建索引,它可以是普通索引、唯一索引或者全文素引, 只要保证该索引只对应表中一个字段即可
创建代码:
==CREATE INDEX 索引名 ON 表名 (字段名1[,字段名2...]);==
==ALTER TABLE 表名 ADD INDEX 索引名 (字段名1[,字段名2...]);==
以上添加代码一定一定要添加括号
联合索引说明:
单列索引多个字段,称为联合索引
触发联合索引的条件有:
假如索引添加形式为:==ALTER TABLE user ADD INDEX test (name,age)==
- **组合约束查询 **
AND(OR查询不会触发索引) ==... WHERE name= '张三' AND age=12==- 单独约束查询 左边第一个字段会触发索引(右边的字段不会触发 ==WHERE name='张三'==
# 唯一索引 (UNIQUE )
使字段的值必须是唯一的(允许null,但只能允许一个空
==CREATE UNIQUE INDEX 索引名 ON 表名 (字段名);==
==ALTER TABLE 表名 ADD UNIQUE INDEX 索引名 (字段名);==
# 全文索引 (FULLTEXT)
只能创建在CHAR、VARCHAR或TEXT类型的字段上, 该索引只有MyISAM存储引擎支持
==CREATE FULLTEXT INDEX 索引名 ON 表名 (字段名);==
==ALTER TABLE 表名 ADD FULLTEXT INDEX 索引名 (字段名);== 注意: 后面需存储引擎(ENGINE =MyISAM)
# 空间索引 (SPATIAL)
只能创建在空间数据类型的字段上。MySQL中的空间数据类型有4种,分别是LGEOMETRY、POINT、 LINESTRING、POLYGON
该索引只有MyISAM存储引擎支持
==CREATE SPATIAL INDEX 索引名 ON 表名 (字段名);==
==ALTER TABLE 表名 ADD SPATIAL INDEX 索引名 (字段名);==
注意: 后面需存储引擎(ENGINE =MyISAM)
# 索引删除
==ALTER TABLE 表名 DROP INDEX 索引名;==
==DROP INDEX 索引名 ON 表名;==
# 函数
# 数学函数
| 函数名称 | 作用 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| SQRT(x) | 返回x的非负2次方根 |
| MOD(x , y) | 返回x被y除后的余数 |
| CEILING(x) / CEIL(x) | 返回 不小于x的最大整数 (前提x有小数) |
| FLOOR(x) | 返回 不大于x的最小整数 (前提x有小数) |
| ROUND(x , y) | 对 x 四舍五入 操作,小数保留 y位 |
| TRUNCATE(x , y) | 对 x 只舍不入 操作,小数保留 y位 |
| SIGN(x) | 返回 x 符号 ( -1 / 0 / 1 ) x为数值,则判断 正或负的值 ;x为其他类型,则返回0 |
# 字符串函数
| 函数名称 | 作用 |
|---|---|
| LENGTH(str) | 返回 字符串的长度 |
| CONCAT(s1 , s2 , .....) | 返回 一个/多个字符串 连接的新字符串 |
| TRIM(str) | 删除字符串两侧的空格 |
| REPLACE(str , s1 , s2) | 使用字符串s2替换字符串str中所有的字符串s1 |
| SUBSTRING(tr , n , len) | 返回字符串st的子串,起始位置为n,长度为len |
| REVERSE(str) | 返回 字符串顺序反转 |
| LOCATE(s1 , str) | 返回 s1 在 str 中的起始位置 |
| UPPER(str) | 将 所有 小写 转换为 大写 |
| LOWER(str) | 将 所有 大写 转换为 小写 |
| FORMAT(str,format) | 将 字符串 进行数据格式化 |
# 日期与时间的函数
| 函数名称 | 作用 |
|---|---|
| CURDATE() | 获取 系统当前 日期 |
| CURTIME() | 获取 系统当前 时间 |
| SYSDATE() | 获取 当前系统 日期和时间 |
| DATE_ADD(now() , INTERVAL num {时间单位}) | 指定过去或未来时间点(num是对现在的时间进行相加) |
| DATEDIFF(d1 , d2) | 计算 两时间 间隔的天数(从0000.1.1开始 n 天后的日期) |
| FROM_DAYS(day) | 计算 时间 得出日期 (从0000.1.1开始 n 天后的日期) |
| YEAR(d) | 获取 日期年份 |
| MONTH(d) | 获取 日期月份 |
| DAY(d) | 获取 日期 日 |
| DATE_FORMAT(date , format) | 日期格式化 format :'%m-%d-%Y' |
点击了解更多日期&时间函数了解 (opens new window)
# 条件判断函数
| 函数名称 | 作用 |
|---|---|
| IF(expr , v1 , v2) | 如果expr表达式为true返回v1,否则返回v2 |
| IFNULL(v1 , v2) | 如果v1不为NULL返回v1,否则返回v2 |
| CASE expr WHEN v1 THEN r1 [WHEN v2 THEN r2......] [ELSE m] END | 如果expr值等于v1、v2等,则返回对应位置THEN后面的结果,否则返回ELSE后的结果m |
# 加密函数
| 函数名称 | 作用 |
|---|---|
| MD5(str) | 对字符串 str 进行MD5加密 |
| ENCODE(str , pwd stu) | 使用pwd作为密码加密字符串str |
| DECODE(str , pwd str) | 使用pwd作为密码解密字符串str |
# 事务
事务指逻辑上的一组操作,组成这组操作的各个单元,要不全部成功,就全部不成功,同一个事务的操作具备同步优点
SET AUTOCOMMIT = 0;
START TRANSACTION; | BEGIN;
···
····
ROLLBACK;
COMMIT;
SET AUTOCOMMIT: 自动事务提交开关(0关闭;1开启) START TRANSACTION | BEGIN: 开启事务(处于事务中,不会影响数据库数据) ROLLBACK: 回滚事务(取消事务,前提是事务未提交前回滚) COMMIT : 事务提交(事务生效后会立即影响数据库数据)
# 事务ACID特性
原子性(Atomicity) 指事务是一个不可分割的工作单位,事务中的操作要么执行成功,要么执行失败
一致性(Consistency) 事务前后数据的完整性必须保持一致(数据库的完整性:如果数据库在某个时间点下,所有的数据都符合所有的约束,则称数据库为符合完整性的状态)
隔离性(Isolation) 指多个用户并发访问数据库时,一个用户的事务不能被其它用户的事务所干扰,多个并发事务之间数据要相互隔离
持久性(Durability) 指一个事务一旦被提交,数据库中的数据改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
# 事务安全问题
脏读: 两事务 某一事务读取到另一个事务修改且未提交的数据
不可重复读: 某一事务多次读取同一条记录的过程,读取的结果不相同过程数据有更改,读取到另一个事务已经提交的数据
虚读(幻读): 某一事务多次查询数据,由于其他事务 新增 或 删除 记录造成多次查询出的记录条数不同
# 事务隔离级别
防止不同隔离性的问题
| 隔离类型 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未读提交 READ UNCOMMITTED | 允许 | 允许 | 允许 |
| 已读提交 READ COMMITTED | 禁止 | 允许 | 允许 |
| 可重复读 REPEATABLE READ | 禁止 | 禁止 | 可能 |
| 顺序读 SERIALIZABLE | 禁止 | 禁止 | 禁止 |
一般默认 可重复读、 已读提交
修改隔离级别 ==SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL 隔离类型;== SESSION: 当前会话 GLOBAL: 全局
查询隔离级别 ==SELECT @@TX_ISOLATION;== (MySQL版本8前) ==SELECT @@TRANSACTION_ISOLATION;== (MySQL版本8后)
# 未读提交 (READ UNCOMMITTED)
读未提交,该隔离级别允许脏读取,其隔离级别是最低的 , 可能出现一个事务读取到另一个未提交的事务
| 时间(T) | 事务A | 事务B |
|---|---|---|
| T1 | 开始事务 | 开始事务 |
| T2 | == | 查余额(500元) |
| T3 | == | 取300元 |
| T4 | 查余额(200元) | == |
| T5 | == | 滚动事务 |
| T6 | 存800元 | == |
| T7 | 提交事务 | == |
| T8 | 取100元 | |
| T9 | 提提交事务 |
最后余额剩1200元。T4 A脏读B修改的数据,T5 B回滚(撤回T5前的所有操作),最后B只提取100元!
# 已读提交 (READ COMMITTED)
读已提交是不同的事务执行的时候 只能获取 到已经提交的数据 . 一个事务多次查询可能得到不一样的结果(其他事务修改并提交了)
| 时间(T) | 事务A | 事务B |
|---|---|---|
| T1 | 开始事务 | 开始事务 |
| T2 | == | 查余额(500元) |
| T3 | 查余额(500元) | == |
| T4 | == | 取500元 |
| T5 | 查余额(500元) | == |
| T6 | == | 提交事务 |
| T7 | 查余额(0) | |
| T8 | 提交事务 |
A只能读取 事务提交后的数据!!
# 可重复读 (REPEATABLE READ)
保证在事务处理过程中,多次读取同一个数据时,该数据的值和事务开始时刻是一致的
| 时间(T) | 事务A | 事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 查所有数据 | 开始事务 |
| T3 | == | 插入一条数据 |
| T4 | == | 提交事务 |
| T5 | 查所有数据(和T2一样) | |
| T6 | 修改范围数据 | |
| T7 | 查所有数据(多了一条数据) | |
| T8 | 提交事务 |
事务A 的 T2 查询数据 与 T5查询数据 是一样的 ,确认数据无误后 对表数据值修改,紧接查询事务多出了一条数据!!(作为这一前提 事务B 插入数据提交事务
事务B未提交 ,事务A 对数据进行更改,则不会显示,除非 事务B提交
# 顺序读 (SERIALIZABLE)
最严格的事务隔离级别。事务以排队形式进行执行。某一事务对数据进行修改必须等另一个 提交 或 回滚 ,才可以进行数据修改!!
# 隔离级别锁的情况
读未提交(RU): 有行级的锁,没有间隙锁。与RC的区别是能够查询到未提交的数据 读已提交(RC): 有行级的锁,没有间隙锁,读不到没有提交的数据 可重复读(RR): 有行级的锁,有间隙锁,每读取的数据都一样,且没有幻读的情况 序列化(S): 有行级锁,也有间隙锁,读表的时候,就已经上锁了
# 锁机制
高并发场景我们也不难发现 , 就是在 双十一 , 春运抢票 , 等等... 在当中也不难发现 , 在巨大流量冲击下 , 数据很有可能会被击穿导致负数等异常现象 , 因此系统需要运用一些技术手段抵抗这巨大流量冲击 .
我们可以通过锁机制来控制数据击穿问题 , 我们分别了解两个锁机制 :
- 悲观锁 在数据进行操作时 , 会进行先加锁 , 执行完后释放锁 , 供给其他线程使用 , 在一个锁执行的过程 , 其他线程则需要等待获取锁
- 乐观锁 不会进行加锁 , 而是在更新数据时检查是否被其他线程修改过 , 从而判断是否进行更改
**区别 : **
| 悲观锁 | 乐观锁 | |
|---|---|---|
| 操作 | 加锁 | 不加锁 |
| 检验 | 业务逻辑层 | SQL操作层 |